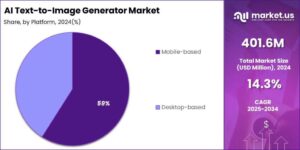
The term “Magnificent Seven” has taken on a new meaning in today’s financial markets, referring to a select group of technology giants that have become the driving force behind major stock indices. Apple, Microsoft, Alphabet, Amazon, Nvidia, Meta, and Tesla collectively represent a significant portion of the S&P 500’s market capitalization and have demonstrated remarkable influence over broader market movements. These companies, each leaders in their respective technological domains, have emerged as key indicators of market sentiment and economic trends, attracting both institutional and retail investors’ attention for their growth potential and market dominance. Machine learning algorithms have revolutionized the way businesses operate, enabling them to extract valuable insights from vast amounts of data. These sophisticated mathematical models learn patterns and relationships within datasets, making predictions and decisions with increasing accuracy over time. The implementation of machine learning solutions has become a critical factor in maintaining competitive advantage across various industries.
Data preprocessing stands as a fundamental step in the machine learning pipeline. Raw data must be cleaned, normalized, and transformed into a suitable format before it can be effectively utilized. This process involves handling missing values, removing outliers, and encoding categorical variables. Feature selection and engineering follow, where relevant attributes are identified and new features are created to enhance the model’s performance.
Supervised learning algorithms require labeled data for training, where the desired output is known. Common applications include classification tasks, such as spam detection or customer churn prediction, and regression problems for forecasting numerical values like sales or stock prices. Popular algorithms in this category include decision trees, random forests, and support vector machines.
Unsupervised learning techniques work with unlabeled data, discovering hidden patterns and structures within the dataset. Clustering algorithms group similar data points together, while dimensionality reduction methods compress data while preserving essential information. These approaches are particularly useful for customer segmentation, anomaly detection, and exploratory data analysis.
Deep learning, a subset of machine learning, utilizes neural networks with multiple layers to process complex patterns. These networks excel at tasks like image recognition, natural language processing, and speech recognition. The availability of powerful computing resources and large datasets has accelerated the advancement of deep learning applications.
Model evaluation and validation ensure the reliability and generalization capability of machine learning solutions. Cross-validation techniques help assess model performance across different data subsets, while metrics like accuracy, precision, and recall provide quantitative measures of success. Regular monitoring and updating of models are essential to maintain their effectiveness over time.
Hyperparameter tuning optimizes model performance by adjusting various configuration settings. This process often involves grid search or random search methods to find the optimal combination of parameters. Advanced techniques like Bayesian optimization can make this process more efficient and effective.
Deployment and scaling of machine learning models present unique challenges. Cloud platforms and containerization technologies facilitate the integration of models into production environments. Real-time prediction services require careful consideration of latency requirements and resource utilization. Version control and model governance ensure reproducibility and compliance with regulatory requirements.
Ethical considerations in machine learning implementations cannot be overlooked. Bias detection and mitigation strategies help ensure fair and equitable outcomes. Privacy-preserving techniques protect sensitive information while maintaining model functionality. Regular auditing of model decisions helps identify and address potential discriminatory patterns.